7. Completing metadata¶
The Metadata Editor makes use of the Data Documentation Initiative (DDI Version 2.5), the Dublin Core (DCMI version X) metadata standards and ISO 19139 for geospatial information.
The table below provides an overview of the different metadata standards as related to the project. Each metadata standard is integrated into the template that will define the project.
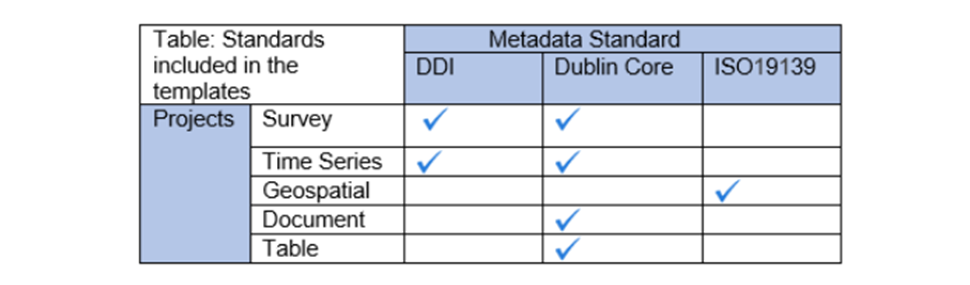
A thorough completion of the DDI and DCMI elements will significantly raise the value of the archiving work by providing users with the necessary information to put the study into its proper context and to understand its purpose.
The DDI requires completion of the following sections: Document Description, Study Description, Datasets, Variables Groups, and External Resources. Recommendations for each field included in the IHSN template are provided below.
| The IHSN recommends using the standardized IHSN DDI/DCMI templates (Study Template and External Resources Template). This Quick Reference Guide is based on these two templates. Visit the IHSN website to download the latest version of these templates, available in multiple languages. |
Overall recommendations:
- As an archivist, you may need to seek assistance from key experts involved in some of the technical aspects of the survey.
- As a general rule, avoid using ALL CAPS when you fill DDI fields. Also, check the spelling of all entries. The Editor does not provide (yet) an automatic spell checker.
- Some of the examples below present an optimal documentation of some fields. In many cases, for past surveys, you will not find such detailed information. Try to provide as much detail as possible. For future surveys, the information should be compiled and provided during the whole life cycle of the survey. This will ensure that the best possible documentation is available at completion of that survey.
7.1. Good practices for completing the Document Description¶
Documenting a study using the DDI and DCMI metadata standards consists of generating a metadata file which will be saved in XML format in what is called an XML Document. The Document Description described below is a description of that XML file. The IHSN Template selected 4 elements to describe the DDI document.
| Metadata Producer | Name of the person(s) or organization(s) who documented the dataset. Use the “role” attribute to distinguish different stages of involvement in the production process. Example: |
|
| Name | Role | |
| National Statistics Office (NSO) | Documentation of the study | |
| International Household Survey Network (IHSN) | Review of the metadata | |
| Date of Production | This is the date (in ISO format YYYY-MM-DD) the DDI document was produced (not distributed or archived). This date will be automatically imputed when you save the file. | |
| DDI Document Version | Documenting a dataset is not a trivial exercise. Producing “perfect” metadata is probably impossible. It may therefore happen that, having identified errors in a DDI document or having received suggestions for improvement, you decide to modify the Document even after a first version has been disseminated. This element is used to identify and describe the current version of the document. It is good practice to provide a version number (and date), and information on what distinguishes this version from the previous one(s) if relevant.
|
|
| DDI Document ID Number | The ID number of a DDI document is a unique number that is used to identify this DDI file. Define and use a consistent scheme to use. Such an ID could be constructed as follows: DDI_COUNTRY_PRODUCER_SURVEY_YEAR where
|
|
| Collection | This field allows viewed and searched the study by collection | |
| Programs | Link surveys to projects / trust funds | |
7.2. Good practices for completing the Study Description¶
In the DDI standard, the Study Description is the section that contains all elements needed to describe the study itself (investigators, dates and methods, scope and coverage, etc.)
| Identification | |
| Survey Title | The title is the official name of the survey as it is stated on the questionnaire or as it appears in the design documents. The following items should be noted:
|
| Survey Subtitle | Subtitle is optional and rarely used. A subtitle can be used to add information usually associated with a sequential qualifier for a survey.
|
| Abbreviation or Acronym | The abbreviation of a survey is usually the first letter of each word of the titled survey. The survey reference year(s) may be included.
|
| Study type | The study type or survey type is the broad category defining the survey. This item has a controlled vocabulary (you may customize the IHSN template to adjust this controlled vocabulary if needed). |
| Series information | A survey may be repeated at regular intervals (such as an annual labour force survey), or be part of an international survey program (such as the MICS, CWIQ, DHS, LSMS and others). The Series information is a description of this “collection” of surveys. A brief description of the characteristics of the survey, including when it started, how many rounds were already implemented, and who is in charge would be provided here. If the survey does not belong to a series, leave this field empty.
|
| Translated title | In countries with more than one official language, a translation of the title may be provided. Likewise, the translated title may simply be a translation into English from a country’s own language. Special characters should be properly displayed (such as accents and other stress marks or different alphabets). |
| Unique user defined ID Number | The ID number of a dataset is a unique number that is used to identify a particular survey. Define and use a consistent scheme to use. Such an ID could be constructed as follows: country-producer-survey-year-vers ion where
|
| Depositor | The name of the person (or institution) who provided this data collection to the archive storing it. |
| Date of Deposit | The date that the data collection was deposited with the archive that originally received it. |
| Version | |
| Version Description | The version description should contain a version number followed by a version label. The version number should follow a standard convention to be adopted by the institute. We recommend that larger series be defined by a number to the left of a decimal and iterations of the same series by a sequential number that identifies the release. Larger series will typically include (0) the raw, unedited dataset; (1) the edited dataset, non anonymized, for internal use at the data producing agency; and (2) the edited dataset, prepared for dissemination to secondary users (possibly anonymized).
A brief description of the version should follow the numerical identification. |
| Production date | This is the date in ISO format (yyyy-mm-dd) of actual and final production of the data. Production dates of all versions should be carefully tracked. Provide at least the month and year. Use the calendar icon in the Metadata editor to assure that the date selected is in compliance with the ISO format. |
| Version Notes | Version notes should provide a brief report on the changes made through the versioning process. The note should indicate how this version differs from other versions of the same dataset. |
| Study Authorization | |
| Authorizing Agency | Name of the agent or agency that authorized the study. The “affiliation” attribute indicates the institutional affiliation of the authorizing agent or agency. The “abbr” attribute holds the abbreviation of the authorizing agent’s or agency’s name |
| Authorization Statement | The text of the authorization. Use XHTML to capture significant structure in the document Example: Required documentation covering the study purpose, disclosure information, questionnaire content, and consent statements was delivered to the OUHS on 2010-10-01 and reviewed by the compliance officer. Statement of authorization for the described study was received on 2010-11-04 |
| Legal basis | Decree or law authorizing or requiring the study (e.g. census act) |
| Overview | |
| Study Budget | Describe the budget of the project in as much detail as needed. Internal structure is allowed using XHTML elements. Different organizations express their budgets in different formats and this open format allows flexibility. Attributes: Budget line ID, Budget line label, Amount, Currency and Source of funding. |
| Abstract | The abstract should provide a clear summary of the purposes, objectives and content of the survey. It should be written by a researcher or survey statistician aware of the survey. |
| Objectives of the study | Describe the Main (explicit) and secondary (explicit) objectives of the survey. |
| Kind of data | This field is a broad classification of the data and it is associated with a drop-down box providing controlled vocabulary. That controlled vocabulary includes 9 items but is not limited to them. |
| Unit of analysis | A survey could have various units of analysis. These are fairly standard and are usually:
|
| Scope | |
| Description of scope | The scope is a description of the themes covered by the survey. It can be viewed as a summary of the modules that are included in the questionnaire. The scope does not deal with geographic coverage.
|
| Topic classifications | A topic classification facilitates referencing and searches in electronic survey catalogs. Topics should be selected from a standard thesaurus, preferably an international, multilingual thesaurus. The IHSN recommends the use of the thesaurus used by the Council of European Social Science Data Archives (CESSDA). The CESSDA thesaurus has been introduced as a controlled vocabulary in the IHSN Study Template version 1.3 (available www.surveynetwork.org/toolkit). |
| Keywords | Keywords summarize the content or subject matter of the survey. As topic classifications, these are used to facilitate referencing and searches in electronic survey catalogs. Keywords should be selected from a standard thesaurus, preferably an international, multilingual thesaurus. Entering a list of keywords is tedious. This option is provided for advanced users only. |
| Quality Statement | |
| Standards Compliance | This section lists all specific standards complied with during the execution of this study. Note the standard name and producer and how the study complied with the standard |
| Other Quality Statement | Enter any additional quality statements |
| Post Evaluation Procedures | |
| Evaluator Type | The evaluator element identifies persons or organizations involved in the evaluation. The Affiliation attribute contains the affiliation of the individual or organization. The Abbr. attribute holds an abbreviation for the individual or organization. The Role attribute indicates the role played by the individual or organization in the evaluation process. Example:
|
| Evaluation Process | Describes the evaluation process followed. Ex-Post Evaluations are frequently done within large statistical or research agencies, in particular when the survey is intended to be repeated or on-going |
| Evaluation Outcomes | Describe the outcomes of the evaluation |
| Coverage | |
| Country | Enter the country name, even in cases where the survey did not cover the entire country. In the field “Abbreviation”, we recommend that you enter the 3-letter ISO code of the country. If the dataset you document covers more than one country, enter all in separate rows. |
| Geographic coverage | This filed aims at describing at what geographic level the data are representative. Typical entries will be “National coverage”, “Urban (or rural) areas only”, “state of …”, “Capital city”, etc. Note that we do not describe here where the data was collected. For example, as sample survey could be declared as “national coverage” even in cases where some districts where not included in the sample, as long as the sampling strategy was such that the representativity is national. |
| Geographic Unit | Lowest level of geographic aggregation covered by the data. |
| Universe | We are interested here in the survey universe (not the universe of particular sections of the questionnaires or variables), i.e. in the identification of the population of interest in the survey. The universe will rarely be the entire population of the country. Sample household surveys, for example, usually do not cover homeless, nomads, diplomats, community households. Population censuses do not cover diplomats. Try to provide the most detailed information possible on the population covered by the survey/census.
|
| Geographic bounding box | The geographic bounding box is the minimum box, defined by west and east longitudes and north and south latitudes, that includes the largest geographic extent of the dataset’s geographic coverage. This element is used in the first pass of a coordinate-based search. If the Geographic bounding Polygon element is included, then this field element MUST be included |
| Geographic Bounding Polygon | This field allows the creation of multiple polygons to describe in a more detailed manner the geographic area covered by the dataset. It should only be used to define the outer boundaries of a covered area. Example: In the United States, such polygons can be created to define boundaries for Hawaii, Alaska, and the continental United States, but not interior boundaries for the contiguous states. This field is used to refine a coordinate-based search, not to actually map an area |
| Producers and Sponsors. | |
| Authoring Entity/Primary investigators | The primary investigator will in most cases be an institution, but could also be an individual in the case of small-scale academic surveys. The two fields to be completed are the Name and the Affiliation fields. Generally, in a survey, the Primary Investigator will be the institution implementing the survey. If various institutions have been equally involved as main investigators, then all should be mentioned. This only includes the agencies responsible for the implementation of the survey, not its funding or technical assistance. The order in which they are listed is discretionary. It can be alphabetic or by significance of contribution. Individual persons can also be mentioned. If persons are mentioned use the appropriate format of Surname, First name. |
| Producers | This field is provided to list other interested parties and persons that have played a significant but not the leading technical role in implementing and producing the data. The specific fields to be competed are: Name of the organization, Abbreviation, Affiliation and Role. If any of the fields are not applicable these can be left blank. The abbreviations should be the official abbreviation of the organization. The role should be a short and succinct phrase or description on the specific assistance provided by the organization in order to produce the data. The roles should be standard vocabulary such as:
Do not include here the financial sponsors. |
| Funding Agency/Sponsor | List the organizations (national or international) that have contributed, in cash or in kind, to the financing of the survey. The government institution that has provided funding should not be forgotten. |
| Other Identifications/ acknowledgements | This optional field can be used to acknowledge any other people and institutions that have in some form contributed to the survey. |
| Sampling | |
| Sampling procedure | This field only applies to sample surveys. Information on sampling procedure is crucial (although not applicable for censuses and administrative datasets). This section should include summary information that includes though is not limited to:
It is useful also to indicate here what variables in the data files identify the various levels of stratification and the primary sample unit. These are crucial to the data users who want to properly account for the sampling design in their analyses and calculations of sampling errors. This section accepts only text format; formulae cannot be entered. In most cases, technical documents will exist that describe the sampling strategy in detail. In such cases, include here a reference (title/author/date) to this document, and make sure that the document is provided in the External Resources.
|
| Sample Frame Name | Sample frame describes the sampling frame used for identifying the population from which the sample was taken. Label and text describing the sample frame |
| Update of listing | Describes operations conducted to update the sample frame |
| Valid Period | Defines a time period for the validity of the sampling frame. Enter dates in YYYY-MM-DD format. |
| Custodian | Custodian identifies the agency or individual who is responsible for creating or maintaining the sample frame. Attribute affiliation provides the affiliation of the custodian with an agency or organization. Attribute abbr. provides an abbreviation for the custodian. |
| Use Statement | Sample frame use statement |
| Frame Unit | Provides information about the sampling frame unit. The attribute “is Primary” is boolean, indicating whether the unit is primary or not. |
| Reference Period | Indicates the period of time in which the sampling frame was actually used for the study in question. Use ISO 8601 date/time formats to enter the relevant date(s). |
| Sample Size | This element provides the targeted sample size in integer format. Attributes: Planned / Actual and Unit and Number. |
| Sample Size Formula | This element includes the formula that was used to determine the sample size |
| Stratification | Describe the Stratification (implicit and explicit) and the Variables identifying strata and PSU |
| Deviation from sample design | This field only applies to sample surveys. Sometimes the reality of the field requires a deviation from the sampling design (for example due to difficulty to access to zones due to weather problems, political instability, etc). If for any reason, the sample design has deviated, this should be reported here. |
| Response rate | Response rate provides that percentage of households (or other sample unit) that participated in the survey based on the original sample size. Omissions may occur due to refusal to participate, impossibility to locate the respondent, or other. Sometimes, a household may be replaced by another by design. Check that the information provided here is consistent with the sample size indicated in the “Sampling procedure field” and the number of records found in the dataset (for example, if the sample design mention a sample of 5,000 households and the data on contain data on 4,500 households, the response rate should not be 100 percent). Provide if possible the response rates by stratum. If information is available on the causes of non-response (refusal/not found/other), provide this information as well. This field can also in some cases be used to describe non-responses in population censuses. |
| Weighting | This field only applies to sample surveys. Provide here the list of variables used as weighting coefficient. If more than one variable is a weighting variable, describe how these variables differ from each other and what the purpose of each one of them is.
|
| Data Collection | |
| Dates of data collection | Enter the dates (at least month and year) of the start and end of the data collection. They should be in the standard ISO format of YYYY-MM-DD. In some cases, data collection for a same survey can be conducted in waves. In such case, you should enter the start and end date of each wave separately, and identify each wave in the “cycle” field. |
| Collector Training | Describes the training provided to data collectors including interviewer training, process testing, compliance with standards etc. This is repeatable for language and to capture different aspects of the training process. The type attribute allows specification of the type of training being described |
| Frequency of Data Collection | For data collected at more than one point in time, the frequency with which the data were collected. The “freq” attribute is included to permit the development of a controlled vocabulary for this element. |
| Time period | This field will usually be left empty. Time period differs from the dates of collection as they represent the period for which the data collected are applicable or relevant. |
| Data Sources | Used to list the book(s), article(s), serial(s), and/or machine-readable data file(s)–if any–that served as the source(s) of the data collection |
| Alternatives to data collection | Sources of data available / potentially considered |
| Mode of data collection | The mode of data collection is the manner in which the interview was conducted or information was gathered. This field is a controlled vocabulary field. Use the drop-down button in the Toolkit to select one option. In most cases, the response will be “face to face interview”. But for some specific kinds of datasets, such as for example data on rain falls, the response will be different. |
| Data Capture | Where was data capture done (e.g., In the field or at the office) and when was data capture done. Also, describe the technology using for data capture (e.g. scanning, PDAs OR Web) |
| Notes on data collection | This element is provided in order to document any specific observations, occurrences or events during data collection. Consider stating such items like:
|
| Questionnaires | This element is provided to describe the questionnaire(s) used for the data collection. The following should be mentioned:
|
| Instrument Development | Describe any development work on the data collection instrument. Type attribute allows for the optional use of a defined development type with or without use of a controlled vocabulary. |
| Review process for survey instrument | Description of the review process / list of agencies/people consulted |
| Pilot/testing of survey instrument and data collection | Description of pilot survey |
| Survey management team | Attributes: Name, Tittle, Agency, Role |
| Data collectors | This element is provided in order to record information regarding the persons and/or agencies that took charge of the data collection. This element includes 3 fields: Name, Abbreviation, the Affiliation and the Role. In most cases, we will record here the name of the agency, not the name of interviewers. Only in the case of very small-scale surveys, with a very limited number of interviewers, the name of person will be included as well. The field Affiliation is optional and not relevant in all cases. The role attribute specifies the role of person in the data collection process.
|
| Compliance with international data collection standards | Describe if the survey comply with international survey recommendations |
| Supervision | This element will provide information on the oversight of the data collection. The following should be considered:
|
| Data Processing | |
| Data entry and editing | The data editing should contain information on how the data was treated or controlled for in terms of consistency and coherence. This item does not concern the data entry phase but only the editing of data whether manual or automatic.
If materials are available (specifications for data editing, report on data editing, programs used for data editing), they should be listed here and provided as external resources.
|
| Software | List of software used for the key activities (especially data entry, editing, tabulation, analysis). Attributes: Purpose and Software |
| Other processing | Use this field to provide as much information as possible on the data entry design. This includes such details as:
Information on tabulation and analysis can also be provided here. All available materials (data entry/tabulation/analysis programs; reports on data entry) should be listed here and provided as external resources.
After all clusters are processed, all data is concatenated together and then the following steps are completed for all data files:
Details of each of these steps can be found in the data processing documentation, data editing guidelines, data processing programs in CSPro and SPSS, and tabulation guidelines. Data entry was conducted by 12 data entry operators in tow shifts, supervised by 2 data entry supervisors, using a total of 7 computers (6 data entry computers plus one supervisors’ computer). All data entry was conducted at the GenCenStat head office using manual data entry. For data entry, CSPro version 2.6.007 was used with a highly structured data entry program, using system controlled approach that controlled entry of each variable. All range checks and skips were controlled by the program and operators could not override these. A limited set of consistency checks were also included in the data entry program. In addition, the calculation of anthropometric Z-scores was also included in the data entry programs for use during analysis. Open-ended responses (“Other” answers) were not entered or coded, except in rare circumstances where the response matched an existing code in the questionnaire. Structure and completeness checking ensured that all questionnaires for the cluster had been entered, were structurally sound, and that women’s and children’s questionnaires existed for each eligible woman and child. 100% verification of all variables was performed using independent verification, i.e. double entry of data, with separate comparison of data followed by modification of one or both datasets to correct keying errors by original operators who first keyed the files. After completion of all processing in CSPro, all individual cluster files were backed up before concatenating data together using the CSPro file concatenate utility. For tabulation and analysis SPSS versions 10.0 and 14.0 were used. Version 10.0 was originally used for all tabulation programs, except for child mortality. Later version 14.0 was used for child mortality, data quality tabulations and other analysis activities. After transferring all files to SPSS, certain variables were recoded for use as background characteristics in the tabulation of the data, including grouping age, education, geographic areas as needed for analysis. In the process of recoding ages and dates some random imputation of dates (within calculated constraints) was performed to handle missing or “don’t know” ages or dates. Additionally, a wealth (asset) index of household members was calculated using principal components analysis, based on household assets, and both the score and quintiles were included in the datasets for use in tabulations. |
| Coding Instructions | |
| Coding Instructions Text | Describe specific coding instructions used in data processing, cleaning, assession, or tabulation. Use this field to describe instructions in a human readable form.
|
| Command | Provide command code for the coding instruction. The formalLanguage attribute identifies the language of the command code.
|
| Data Appraisal | |
| Estimate of sampling error | For sampling surveys, it is good practice to calculate and publish sampling error. This field is used to provide information on these calculations. This includes:
|
| Other forms data appraisal | This section can be used to report any other action taken to assess the reliability of the data, or any observations regarding data quality. This item can include:
The results of each of these data quality tables are shown in the appendix of the final report and are also given in the external resources section. The general rule for presentation of missing data in the final report tabulations is that a column is presented for missing data if the percentage of cases with missing data is 1% or more. Cases with missing data on the background characteristics (e.g. education) are included in the tables, but the missing data rows are suppressed and noted at the bottom of the tables in the report (not in the SPSS output, however). |
| Data Access | |
| Access authority | This section is composed of various sections: Name-Affiliation-email-URI. This information provides the contact person or entity to gain authority to access the data. It is advisable to use a generic email contact such as data@popstatsoffice.org whenever possible to avoid tying access to a particular individual whose functions may change over time. |
| Confidentiality Declaration | If the dataset is not anonymized, we may indicate here what Affidavit of Confidentiality must be signed before the data can be accessed. Another option is to include this information in the next element (Access conditions). If there is no confidentiality issue, this field can be left blank. An example of statement could be the following: Confidentiality of respondents is guaranteed by Articles N to NN of the National Statistics Act of [date]. Before being granted access to the dataset, all users have to formally agree:
This statement does not replace a more comprehensive data agreement(see Access condition). |
| Access conditions | Each dataset should have an “Access policy” attached to it. The IHSN recommends three levels of accessibility:
The IHSN has formulated standard, generic policies and access forms for each one of these three levels (which each country can customize to its specific needs). One of the three policies may be copy/pasted in this field once it has been edited as needed and approved by the appropriate authority. Before you fill this field, a decision has to be made by the management of the data depositor agency. Avoid writing a specific statement for each dataset. If the access policy is subject to regular changes, you should enter here a URL where the user will find detailed information on access policy which applies to this specific dataset. If the datasets are sold, pricing information should also be provided on a website instead of being entered here. If the access policy is not subject to regular changes, you may enter more detailed information here. For a public use file for example, you could enter information like: The dataset has been anonymized and is available as a Public Use Dataset. It is accessible to all for statistical and research purposes only, under the following terms and conditions:
|
| Citation requirement | Citation requirement is the way that the dataset should be referenced when cited in any publication. Every dataset should have a citation requirement. This will guarantee that the data producer gets proper credit, and that analytical results can be linked to the proper version of the dataset. The Access Policy should explicitly mention the obligation to comply with the citation requirement (in the example above, see item 5). The citation should include at least the primary investigator, the name and abbreviation of the dataset, the reference year, and the version number. Include also a website where the data or information on the data is made available by the official data depositor.
|
| Location of Data Collection | Location where the data collection is currently stored. Use the URI attribute to provide a URN or URL for the storage site or the actual address from which the data may be downloaded. |
| URL for Location of Data Collection | Location where the data collection is currently stored. Provide a URN or URL for the storage site or the actual address from which the data may be downloaded. |
| Archive Where Study Originally Stored | Statement of collection availability. An archive may need to indicate that a collection is unavailable because it is embargoed for a period of time, because it has been superseded, because a new edition is imminent, etc. It is anticipated that a controlled vocabulary will be developed for this element. |
| Availability Status | Statement of collection availability. An archive may need to indicate that a collection is unavailable because it is embargoed for a period of time, because it has been superseded, because a new edition is imminent, etc. It is anticipated that a controlled vocabulary will be developed for this element. |
| Deposit Requirement | Information regarding user responsibility for informing archives of their use of data through providing citations to the published work or providing copies of the manuscripts. |
| Disclaimer and Copyright | |
| Disclaimer | A disclaimer limits the liability that the Statistics Office has regarding the use of the data. A standard legal statement should be used for all datasets from a same agency. The IHSN recommends the following formulation: The user of the data acknowledges that the original collector of the data, the authorized distributor of the data, and the relevant funding agency bear no responsibility for use of the data or for interpretations or inferences based upon such uses. |
| Copyright | Include here a copyright statement on the dataset, such as: © 2017, Popstan Central Statistics Agency |
| Contacts | |
| Contact persons | Users of the data may need further clarification and information. This section may include the name-affiliation-email-URI of one or multiple contact persons. Avoid putting the name of individuals. The information provided here should be valid for the long term. It is therefore preferable to identify contact persons by a title. The same applies for the email field. Ideally, a “generic” email address should be provided. It is easy to configure a mail server in such a way that all messages sent to the generic email address would be automatically forwarded to some staff members.
|
7.3. Good practices for completing the File Description¶
The File Description is the DDI section that aims to provide a detailed description of each data file. The IHSN has selected six of the available DDI elements.
| File Citation | Provides for a full bibliographic citation option for each data file described in File Description. |
| Contents of Files | A data filename usually provides little information on its content. Provide here a description of this content. This description should clearly distinguish collected variables and derived variables. It is also useful to indicate the availability in the data file of some particular variables such as the weighting coefficients. If the file contains derived variables, it is good practice to refer to the computer program that generated it.
|
| File Producer | Put the name of the agency that produced the data file. Most data files will have been produced by the survey primary investigator. In some cases however, auxiliary or derived files from other producers may be released with a data set. This may for example include CPI data generated by a different agency, or files containing derived variables generated by a researcher. |
| Version | A data file may undergo various changes and modifications. These file specific versions can be tracked in this element. This field will in most cases be left empty. It is more important to fill the field identifying the version of the dataset (see above). |
| Processing Checks | Use this element if needed to provide information about the types of checks and operations that have been performed on the data file to make sure that the data are as correct as possible, e.g. consistency checking, wildcode checking, etc. Note that the information included here should be specific to the data file. Information about data processing checks that have been carried out on the data collection (study) as a whole should be provided in the “Data editing” element at the study level. You may also provide here a reference to an external resource that contains the specifications for the data processing checks (that same information may be provided also in the “Data Editing” filed in the Study Description section). |
| Files Notes | This field, aiming to provide information to the user on items not covered elsewhere, will in most cases be left empty. |
7.4. Good practices for completing the Variables Description¶
The Variable Description is the section of the DDI document that provides detailed information on each variable.
| VARIABLES | |
| Names | These are the names given to the variables. Ideally, the variable names should be a maximum of 8 characters, and use a logical naming convention (e.g., section (S) and question (Q) numbers to name the question). If the variable names do not follow these principles, DO NOT CHANGE THE VARIABLE NAMES IN THE EDITOR, but make recommendations to the data processor for consideration for future surveys. |
| Labels | All variables should have a label that
Recommendations:
|
| Width, StartCol, Endcol | When you import your data files from Stata or SPSS, the information on StartCol and EndCol will be empty. It is crucial to add this information, in order to allow users to export the data to ASCII fixed format. To do so, use the “Variables > Resequence” function in the Editor, for each data file. |
| Data type | Four types of variables are recognized by the Editot:
The data type is usually properly identified when the data is imported. It is important to avoid the use of string variables when this is not absolutely needed. Such issues must be taken care of before the data is imported in the Editor. See the section on “1. Gathering and preparing the dataset” above. |
| Measure | The Metadata Editor will allow you to define the measure of a variable as:
|
| CATEGORIES | |
| Categories | Variable categories are the lists of codes (and their meaning) that apply to the variable. The Editor imports categories and their labels from the source data files (SPSS, Stata). If necessary, add/edit the codes. Use the Documentation > Create categories from statistics if the source dataset did not include value labels (e,g., when imported from ASCII). Do not include codes for “Missing”. The codes for Missing must be specified in the “Missing data” field. If you fail to do that, the summary statistics (mean, standard deviation, etc) will be calculated including the missing code, which will be considered as a valid value. 
|
| VARIABLE INFORMATION | |
| Time variable | This is a check-box used to tag and identify variables used to define time. |
Min Max |
Allows modifying the minimum value of a variable. For each variable where it makes sense, you should check that the Min and Max values are correct. Remember: if a specific value is used for “Missing”, this should not be included in the Min-Max range. For example, if codes 1 and 2 are used for Male and Female, and 9 for unknown sex, then the Min will be 1 and the Max will be 2. The code 9 must be listed in the “Missing” codes (see below). |
| Decimals | Defines the number of decimal places of a numeric variable type. |
| Implicit decimals | This check box is selected only when a fixed ASCII-type file is imported and the data file includes a decimal character. As the decimal character also requires a space in the variable length assignation, it is important to check this box in order to assure proper alignment of the data. |
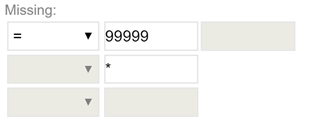
| Missing data | Missing values are those values that are blank in a data file but should have been responses and are within the path or universe of the questionnaire. Missing values should always be coded. Missing values should be differentiated from “not applicable” and zero (0) values. |
| STATISTICS | |
| Statistics Options | Various options exist for displaying and presenting summary information of the variable to the user or the person browsing the output. Summary statistics are saved in the DDI document and become part of the metadata. It is therefore important to select the appropriate ones.
Make sure you do not include “Frequencies” for variables such as the household identification number or enumeration area. This would produce a useless frequency table, that would considerably increase the size of your DDI file (in general, a very large DDI file–8 to 10Mb or more– indicates such a problem). Make sure also that you do not include meaningless summary statistics, such as the mean or standard deviation calculated on the codes used for variable SEX. Notes:
|
| DOCUMENTATION | |
| Definition | This element provides a space to describe the variable in detail. Not all variables require definition. The following variables should always be defined when available in a questionnaire:
|
| Universe | The universe at the variable level reflects skip patterns within-records in a questionnaire. This information can typically be copy/pasted from the survey questionnaire. Try to be as specific as possible. This information is very useful for the analyst. In many cases, a block of variables will have the same universe (for example, a block of variables on education can all relate to the “Population aged 6 to 24 year). The Toolkit allows you to select multiple variables and enter the universe information to all variables at once. |
| Source of information | Enter information regarding who provided the information contained within the variable. In most cases, the source will be “Head of household” or “Household member”. But it may also be:
|
| Concepts | Greater description on the nature of the variable can be placed in this element. For example, this element can provide a clearer definition for certain variables (i.e. a variable that provides information on whether a person is a household member). In the case of household membership, a conceptual definition can be provided.
|
Pre-question text Literal question Post-question text |
The pre-question texts are the instructions provided to the interviewers and printed in the questionnaire before the literal question. This does not apply to all variables. Do not confuse this with instructions provided in the interviewer’s manual. With this and the next two fields, one should be able to understand how the question was asked during the interview. See example below. The literal question is the full text of the questionnaire as the enumerator is expected to ask it when conducting the interview. This does not apply to all variables (it does not apply to derived variables). The post-question texts are instructions provided to the interviewers, printed in the questionnaire after the literal question. Post-question can be used to enter information on skips provided in the questionnaire. This does not apply to all variables. Do not confuse this with instructions provided in the interviewer’s manual. With this and the next two fields, one should be able to understand how the question was asked during the interview. See example above.

|
| Interviewer Instruction | Copy/paste the instructions provided to the interviewers in the interviewer’s manual. In cases where some instructions relate to multiple variables, repeat the information in all variables. The Editor allows you to select multiple variables and enter the information to all these variables at once. |
| Imputation | The field is provided to record any imputation or replacement technique used to correct inconsistent or unreasonable data. It is recommended that this field provide a summary of what was done and include a reference to a file in the external resources section. |
| Recoding and derivation | This element applies to data that were obtained by recoding collected variables, or by calculating new variables that were not directly obtained from data collection. It is very important to properly document such variables. Poorly documented variables cannot (or should not) be used by researchers. In cases where the recoding or derivation method was very simple, a full description can be provided here. For example, if variable AGE_GRP was obtained by recoding variable S1Q3, we could simply mention “Variable obtained by recoding the age in years provided in variable S1Q3 into age groups for years 0-4, 5-9, …, 60-64, 65 and over. Code 99 indicates unknown age.” When the derivation method is more complex, provide here a reference to a document (and/or computer program) to be provided as an External Resource. This will be the case for example for a variable “TOT_EXP” containing the household annual total expenditure, obtained from a household budget survey. In such case, the information provided here could be: “This variable provides the annual household expenditure. It was obtained by aggregating expenditure data on all goods and services, available in sections 4 to 6 of the household questionnaire. It contains imputed rental values for owner-occupied dwellings. The values have been deflated by a regional price deflator available in variable REG_DEF”. All values are in local currency. Outliers have been fixed. Details on the calculations are available in Appendix 2 of the Report on Data Processing, and in the Stata program “aggregates.do” available in external resources.” |
| Security | This field will be left empty in most cases. It can be used to identify variables that are direct identifiers of the respondents (or highly identifying indirect identifiers), and that should not be released. |
| Notes | This element is provided in order to record any additional or auxiliary information related to the specific variable. |
7.5. Good practices for completing the External Resources description¶
The External Resources are all materials related to the study others than the data files. They include documents (such as the questionnaires, interviewer’s manuals, reports, etc), programs (data entry, editing, tabulation, and analysis), maps, photos, and others. To document external resources, the Metadata Editor uses the Dublin Core metadata standard (which complements the DDI standard).
| Label | This is the label that will be used to display a hyper link to the attached document. It can be the title, name, or an abbreviated version of the title. |
| Resource | The resource is used to point to the file that will be attached and distributed. The folder where the document is found is a relative path and should be the folder that will be pasted into the document path. Once you have pointed to the specified resource make sure you check file access by clicking the folder icon to the right of the entry field. |
| Type | This is crucial information. A controlled vocabulary is provided. The selection of the type is important as it determines the way it will be presented or displayed to the user in the final output. The following are the choices:
|
| Title | Full title of the document as it is provided on the cover page. |
| Subtitle | Subtitle if relevant. |
| Author(s) | Include all authors that are listed on the report. |
| Date Created | Date of the publication of the report or resource (at least month and year). For reports, this is most likely stated on the cover page of the document. For other types of resources, put here the date the resource was produced. |
| Country | The country (or countries) that are covered by the associated document. |
| Language | Use the Language element to list all languages which appear in a resource. The languages should be selected from the drop-down list, and each language should appear on its own line. The proposed controlled vocabulary is based on ISO 639-3s. |
| Format | The file format provides information on the kind of electronic document being provided. This includes: PDF, Word, Excel etc. This is a controlled vocabulary. If the controlled vocabulary does not provide the format you need, type it (or add it in the controlled vocabulary using the Editor Template Editor). Providing information on the format will inform the user on the software needed to open the file. |
| ID Number | If there is a unique ID number which references the document (such as a Library of Congress number or a World Bank Publication number) include this as the ID Number. |
| Contributor(s) | Include the names of all organizations that have been involved or contributed to producing the publication. This included funding sources as well as authoring entities. |
| Publisher(s) | Include the official organization(s) accredited with disseminating the report. |
| Rights | Some resources are protected by copyrights. Use the Rights element to provide a clear and complete description of the usage rights if relevant. |
| Description | A brief description of the resource. |
| Abstract | An abstract of the content of the resource. |
| Table of Contents | Use the Table of Contents element to list all sections of a report, questionnaire, or other document. When copying a table of contents from another file into a project, pay close attention to the formatting as tabs, indents, and fonts may not be preserved. Because the text cannot be formatted, adopting strategies such as placing chapter titles in capital letters can help keep a table of contents organized. Including page numbers is not crucial. |
| Subjects | The key topics discussed in the resource can be listed in the Subjects element. Although the IHSN Resource Template does not include a controlled vocabulary for this element, organizations may opt to modify the template and establish a set list of subjects which all of their projects should use when documenting studies. |